The landscape of enterprise technology has undergone a seismic shift. Just three years ago, integrating Artificial Intelligence into a B2B SaaS platform meant using basic, deterministic machine learning algorithms for predictive analytics or linear regressions. Today, we stand on the verge of Artificial General Intelligence (AGI). For modern enterprises, deploying sophisticated Large Language Models (LLMs) and autonomous agents is no longer an experimental luxury it is a core operational necessity.
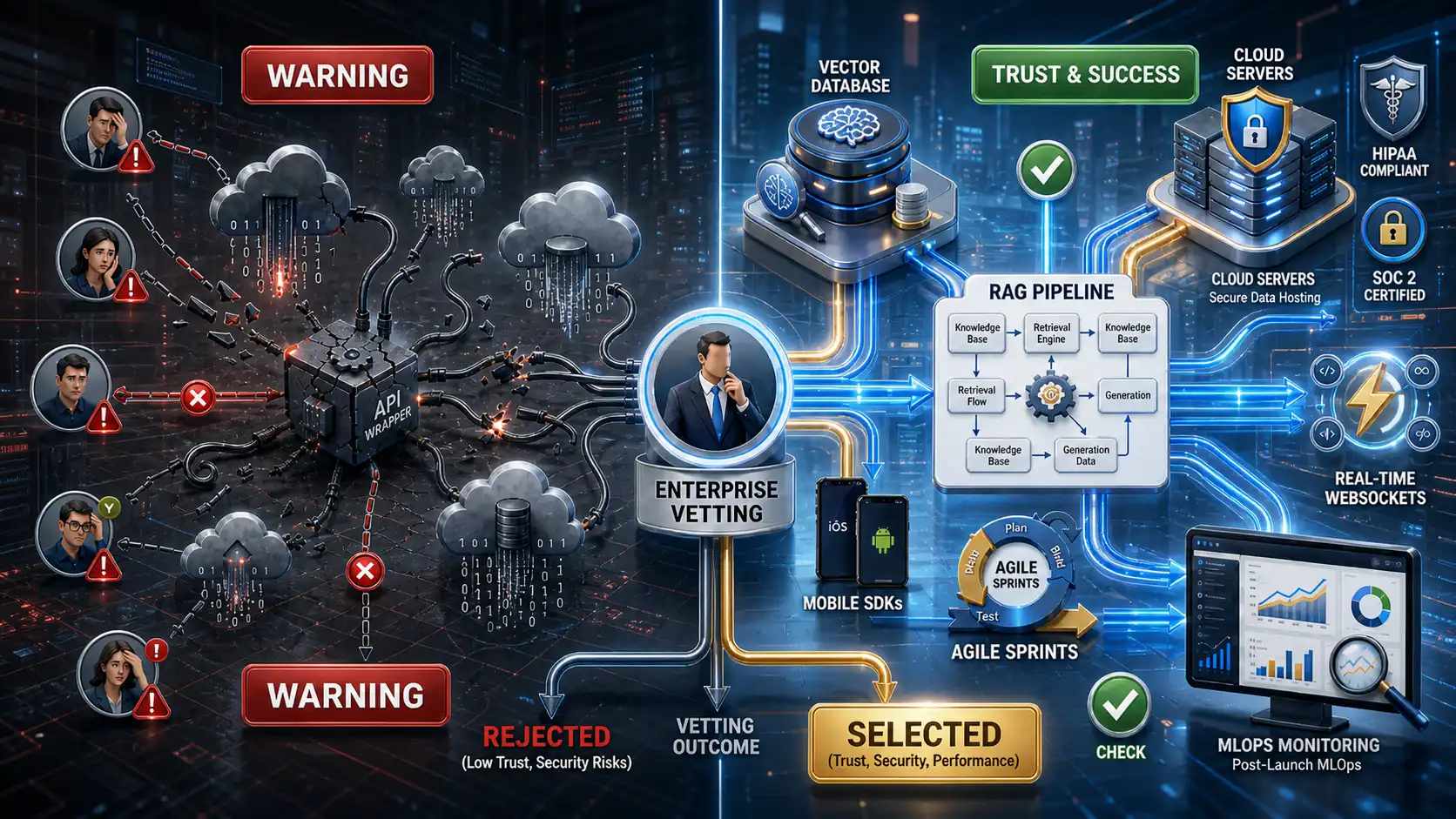
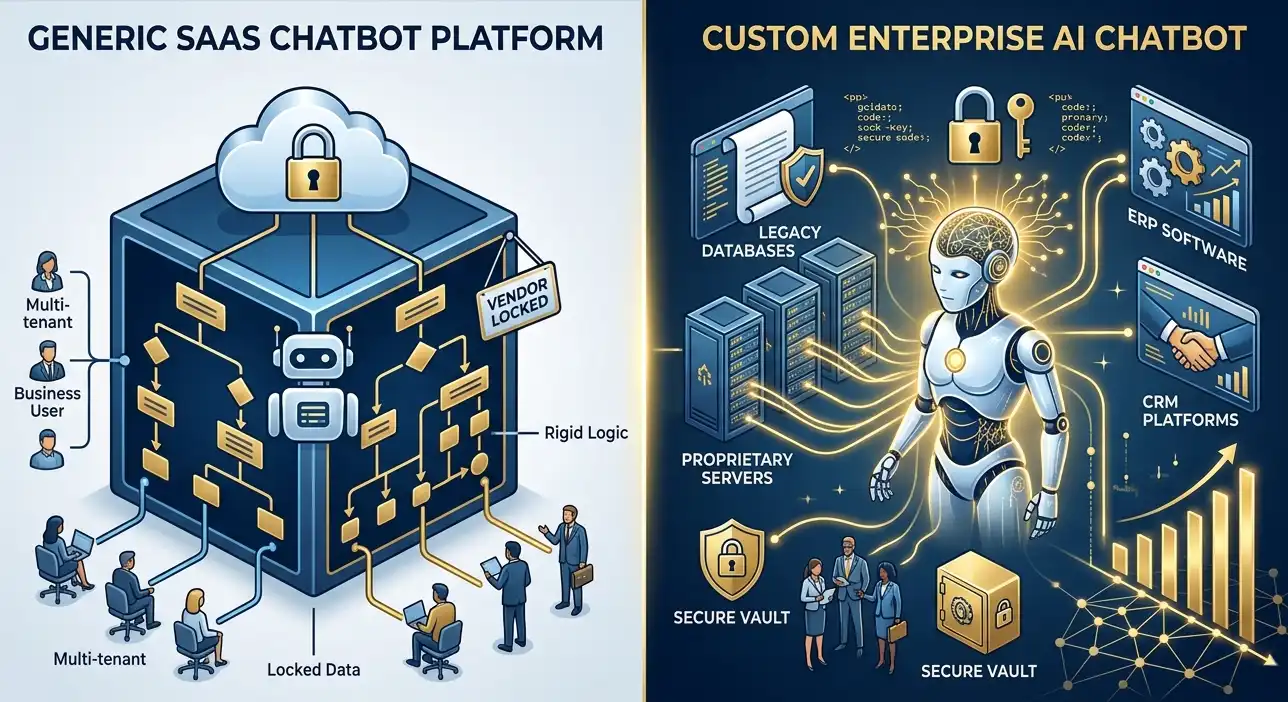
However, jumping from standard SaaS development (using React, Node.js, and SQL) to generative AI software development requires a complete reimagining of your engineering pipeline. Chief Technology Officers (CTOs) and VPs of Engineering are quickly realizing that simply building API wrappers around public models like ChatGPT is a flawed strategy. True competitive advantage, data security, and operational scalability lie in building proprietary, deeply integrated AI ecosystems.
In this comprehensive, 3,000+ word enterprise AI development guide, we will break down the entire AI software lifecycle from the ground up. We will explore the underlying mathematics of foundation models, the exact infrastructure required to host them, the rigorous data security protocols needed for compliance, and how to accurately calculate your Total Cost of Ownership (TCO).
If your organization is looking to bypass the costly trial-and-error phase entirely, MindRind provides elite custom generative ai development services. We architect secure, production-ready AI systems tailored to your exact business constraints and data requirements.

Chapter 1: Unpacking the Generative AI Tech Stack
Before your engineering team writes a single line of Python, technical leaders must understand the modern Generative AI Technology Stack. Generative AI is not traditional software; it is probabilistic, data-heavy, and relies heavily on deep learning and neural networks.
The modern AI stack is divided into four distinct layers:
The Compute & Infrastructure Layer
Generative AI requires massive computational power. Traditional CPUs are virtually useless for training or running large models; you need GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units).
- Cloud Providers: AWS (Trainium/Inferentia chips), Google Cloud Platform (TPUs), and Microsoft Azure are the backbone of AI hosting.
- On-Premise vs. Cloud: For highly regulated industries, building an on-premise GPU cluster is becoming popular again to ensure data never leaves the building.
The Foundation Model Layer
At the heart of any generative AI application is the Foundation Model. These are massive neural networks trained on vast amounts of unstructured data using the “Transformer” architecture (first introduced by Google in 2017). Large Language Models (LLMs) are a subset of foundation models specifically optimized for Natural Language Processing (NLP). When planning your architecture, you must decide whether to rely on closed-source APIs (like OpenAI’s GPT-4 or Anthropic’s Claude 3) or host your own weights using open-source models (like Meta’s Llama 3 or Mistral). To make the right choice for your data privacy and control, we highly recommend reading our deep-dive technical comparison on open-source vs proprietary models.
The Orchestration & Data Layer
An LLM on its own is just a text generator. To make it a functional piece of software, you need an orchestration layer.
- Frameworks: Tools like LangChain and LlamaIndex act as the “glue” that connects your LLM to your databases, APIs, and user interfaces.
- Vector Databases: Traditional SQL databases cannot store the complex, multi-dimensional concepts that AI understands. You must use Vector Databases (like Pinecone, Milvus, or Weaviate) to store data as mathematical “embeddings.”
The Application Layer
This is the front-end interface where your users (or internal employees) interact with the AI. It could be a conversational chatbot, an automated coding assistant in an IDE, or an invisible agent operating in the background of your CRM.

Chapter 2: Designing Your Enterprise AI Architecture
Once you understand the underlying technology stack, the next phase in generative AI software development is architectural design. How you structure your data pipeline will dictate the latency, factual accuracy, and scalability of your AI application.
The Great Architectural Debate: RAG vs. Fine-Tuning
Out of the box, foundation models know absolutely nothing about your company’s proprietary data. If you ask a baseline model about your latest Q3 financial report, it will either say “I don’t know” or, worse, it will “hallucinate” (invent a fake answer).
To make an AI useful for your specific B2B operations, you must inject your data into the model.
There are two primary engineering methodologies to achieve this:
- Retrieval-Augmented Generation (RAG): RAG is currently the industry standard for enterprise data integration. Instead of changing the model itself, RAG changes the prompt.
- How it works: When a user asks a question, the system first searches your secure Vector Database for relevant company documents. It retrieves these documents and feeds them to the LLM alongside the user’s question, essentially saying: “Answer the user’s question using ONLY this provided document.”
- Why it wins: It eliminates hallucinations and allows for real-time data updates.
- Model Fine-Tuning: This involves taking an open-source model and continuing its training on your specific dataset. This requires heavy compute power and physically alters the model’s internal weights and neural pathways.
- How it works: You feed the model thousands of examples of how you want it to behave.
- Why it wins: It is perfect for teaching an AI a highly specific tone of voice, a new programming language, or a strict output format (like generating perfectly structured JSON files).
Which one should your engineering team choose? It depends entirely on your specific use case. We break down the exact technical differences, implementation timelines, and pros/cons in our complete architectural comparison of RAG vs. Fine-Tuning.
Structuring for High-Traffic Scale
A prototype built on a single developer’s laptop using a Jupyter Notebook is vastly different from a production environment handling millions of concurrent API calls. To handle enterprise-level traffic, you need a robust, fault-tolerant architecture. This includes setting up API gateways, load balancers, rate limiting, and semantic caching (to save costs on repeated questions).
For a complete engineering blueprint on setting this up, explore our guide on building a scalable LLM architecture.

Chapter 3: The AI Software Development Lifecycle (SDLC)
Developing generative AI requires a completely different Software Development Lifecycle (SDLC) compared to traditional Agile or Waterfall methodologies. In AI, code is secondary; Data is primary.
Phase 1: Data Curation and Pre-Processing
Generative AI operates on the principle of “Garbage In, Garbage Out.” If you feed your LLM messy, contradictory, or outdated PDF files, the AI will give messy and contradictory answers.
- ETL Pipelines: You must build Extract, Transform, and Load (ETL) pipelines to clean your data.
- Chunking Strategy: When storing data in a vector database, you cannot just upload a 500-page manual. You must “chunk” the data into semantic paragraphs so the AI can retrieve the exact sentence it needs.

Phase 2: Prompt Engineering and Guardrails
Before writing backend logic, AI engineers spend weeks optimizing prompts. This is not just typing questions; this involves “System Prompts” that strictly define the AI’s persona, its limitations, and its ethical boundaries.
Phase 3: MLOps and Continuous Evaluation
In traditional software, if a button works today, it works tomorrow. In AI, models suffer from “Drift.” As language evolves or base models are updated by providers like OpenAI, your AI’s behavior can unexpectedly change. Machine Learning Operations (MLOps) is the practice of continuously monitoring your AI’s outputs. You must set up automated evaluation frameworks (like RAGAS or TruLens) to mathematically score your AI’s accuracy, relevance, and toxicity on a daily basis.

Chapter 4: Enterprise AI Security & Compliance
The number one objection from board members and Chief Information Security Officers (CISOs) regarding generative AI adoption is data privacy. And their fears are entirely justified.
When you integrate a Large Language Model into your enterprise operations, you are passing highly sensitive company data, source code, and potentially Personally Identifiable Information (PII) of your customers through massive neural networks. If this is done incorrectly using public API endpoints (like the consumer version of ChatGPT), your proprietary data could be stored and used to train future public models. This leads to catastrophic data leaks and regulatory fines.
Building a Defensive AI Posture
Enterprise-grade generative AI requires military-grade security. A traditional firewall is not enough. Your AI architecture must include:
- Virtual Private Clouds (VPC) & On-Prem Deployment: For ultimate security, models (especially open-source ones like Llama 3) should be hosted within your own VPC. The data never leaves your internal network.
- Dynamic Data Masking: Before a user’s prompt is sent to the LLM, an intermediate sanitization layer must automatically identify and strip out PII (like Social Security Numbers or credit card details).
- Role-Based Access Control (RBAC) in Vector Databases: If a junior employee asks the AI a question, the AI should only retrieve context from documents that the junior employee has clearance to read. Your vector database must inherit your company’s Active Directory permissions.
- Prompt Injection Defense: Hackers can use clever language tricks to bypass an AI’s instructions, forcing it to execute malicious code or reveal hidden data. You must implement input-validation guardrails to neutralize these attacks.
Compliance with frameworks like SOC 2, GDPR, and HIPAA is non-negotiable. To ensure your engineering team is building defensive systems from day one, it is mandatory to read our technical guide on preventing proprietary data leaks in generative AI.
Chapter 5: High-ROI Applications and Industry Use Cases
Generative AI is a horizontal technology meaning it is industry-agnostic but its implementation must be highly specialized. The Return on Investment (ROI) of a generative AI software development project depends entirely on how deeply it integrates into your daily workflows.
Let’s explore how different sectors are moving beyond the “chatbot phase” and building real enterprise value.
Healthcare and Financial Services (High-Stakes AI)
Highly regulated industries require precise, deterministic outputs. A generative AI cannot “guess” a medical diagnosis or a tax calculation. In the financial sector, AI is being deployed for predictive market analytics, real-time fraud detection, and the automated generation of complex audit trails. In healthcare, it is revolutionizing the summarization of Electronic Health Records (EHR) and accelerating drug discovery. Because these sectors have zero tolerance for AI hallucinations, stringent architectural guardrails are required. We have compiled the top compliant solutions for finance and healthcare to guide your strategic planning.
Next-Generation Customer Support Automation
The days of frustrating, rule-based, decision-tree chatbots are officially over. Modern enterprises are building conversational AI agents that understand context, nuance, user sentiment, and multi-turn conversations. However, the biggest risk in customer-facing AI is the “hallucination” factor—when an AI confidently gives a customer the wrong refund policy or invents a fake feature. By combining RAG architectures with strict system prompts, you can build enterprise-grade chatbots that don’t hallucinate, ensuring your brand reputation remains intact while drastically reducing your customer support overhead.
Augmenting Software Engineering Teams
Perhaps the most lucrative application of generative AI for B2B tech companies is using it to write software. We are moving past simple auto-complete tools. Today, you can integrate autonomous AI agents directly into your CI/CD pipelines. These agents can automatically review pull requests, write unit tests, generate documentation from legacy codebases, and even translate code from outdated languages (like COBOL) to modern frameworks (like Rust or Go). Discover how your CTO can leverage generative AI for software development teams to reduce technical debt and exponentially speed up your time-to-market.

Chapter 6: The Economics of Generative AI (Cost & ROI)
A common pitfall for enterprise leaders is underestimating the Total Cost of Ownership (TCO) for an AI initiative. Building AI is not cheap. It requires massive compute power, expensive cloud infrastructure, and ongoing MLOps maintenance.
Technical leaders must calculate the TCO before presenting the project to the board. The economics of AI software development can be broken down into three main categories:
- You pay per “token” (roughly parts of words) that you send to the API and receive back. For high-volume applications, this can quickly scale to tens of thousands of dollars per month.
- Infrastructure & GPU Costs: If you choose to host your own open-source models, you must rent GPU clusters from AWS, Azure, or GCP. High-end GPUs like the NVIDIA H100 are incredibly expensive to run 24/7.
- Development & Maintenance (MLOps): The initial software development is just the beginning. Maintaining data pipelines, monitoring for model drift, and continually updating vector databases requires a dedicated team
To accurately plan your IT budget for the upcoming year, you must understand all these variables. Get a precise, mathematically driven breakdown of the overall custom generative AI development cost before you begin your build.
Chapter 7: The Talent Bottleneck – Hiring vs. Outsourcing
The single biggest bottleneck in generative AI software development today is not access to compute power; it is the global talent shortage. Standard full-stack developers (React/Node) cannot simply transition to building LLM architectures overnight. The math, the logic, and the deployment environments are fundamentally different.
Building an In-House AI Division
If you choose to build a team internally, you are entering a highly competitive market. You need Machine Learning Engineers, Ph.D. Data Scientists, and AI Operations (AIOps) specialists. Furthermore, you must know exactly what skills to look for when hiring a generative AI developer, such as deep expertise in PyTorch, TensorFlow, advanced vector calculus, and prompt engineering orchestration.
The Outsourcing Advantage
Recruiting, interviewing, and onboarding an elite internal AI team can take 6 to 12 months. In the AI arms race, being a year late means losing market share to competitors who moved faster. For the vast majority of B2B enterprises, partnering with a specialized AI agency is the smarter financial and strategic move. It allows you to bypass the talent shortage, eliminate the technical learning curve, and achieve immediate speed-to-market. For a detailed comparison of the risks, rewards, and timelines, read our comprehensive analysis on hiring a generative AI development company versus building an in-house division.
Conclusion: The Future is Generative
Generative AI software development is fundamentally redefining how businesses operate. We are transitioning from an era where humans command computers via code, to an era where humans collaborate with computers via natural language.
From orchestrating complex LLM architectures and vector databases, to securing enterprise data within VPCs, and optimizing cloud GPU costs the technical journey is complex but the financial rewards are unprecedented. The enterprises that master this technology today will completely dominate their respective industries tomorrow.
At MindRind, we take the guesswork, the security risks, and the talent acquisition headaches out of AI engineering. Our team of elite machine learning engineers builds secure, scalable, and hallucination-free generative AI applications that drive measurable business value.
Ready to turn your AI vision into a production-ready reality? Contact MindRind today to discuss your architecture and begin building the future.
Frequently Asked Questions
Traditional software development relies on deterministic, rule-based logic (If/Then statements) written in languages like Java or Node.js. Generative AI development is probabilistic. It involves orchestrating Large Language Models (LLMs), managing vector databases, optimizing neural network parameters, and utilizing MLOps to handle unstructured data.
The cost varies heavily based on your architecture. A simple AI wrapper using public APIs may cost a few thousand dollars, while a highly secure, enterprise-grade RAG pipeline hosted on a Virtual Private Cloud (VPC) can range from $50,000 to over $200,000. Ongoing costs include cloud compute (GPUs), API tokenization, and MLOps maintenance.
To prevent data leaks, enterprises should avoid sending sensitive data to public APIs like the consumer version of ChatGPT. Instead, secure AI architectures utilize Virtual Private Clouds (VPCs), dynamic data masking, Role-Based Access Control (RBAC), and locally hosted open-source models (like Llama 3) to maintain strict SOC 2, GDPR, and HIPAA compliance.
RAG is an AI architecture that connects an LLM to your company’s private data. It converts your documents into mathematical vectors, stores them in a vector database (like Pinecone), and retrieves the relevant information when a user asks a question. This allows the AI to give highly accurate, company-specific answers without needing expensive model retraining.
AI hallucinations occur when a model lacks context and invents facts. To stop this, engineering teams must implement a strict RAG pipeline combined with low “temperature” settings and semantic guardrails. This mathematically forces the AI to base its answers strictly on the retrieved context rather than its pre-trained global knowledge.
Proprietary APIs (like OpenAI’s GPT-4) are excellent for rapid prototyping and complex general reasoning. However, for maximum data privacy, lower scalable compute costs, and full control over model weights, enterprises are increasingly adopting fine-tuned open-source models (like Meta Llama 3 or Mistral) hosted on their own infrastructure.
Building enterprise AI requires specialized Machine Learning Engineers. Key skills include proficiency in Python, deep learning frameworks (PyTorch, TensorFlow), orchestration tools (LangChain, LlamaIndex), vector calculus, prompt engineering, and MLOps deployment.
Due to the severe global shortage of AI talent, building an in-house team can take 6 to 12 months and involves extremely high payroll costs. Outsourcing to an elite generative AI development firm allows enterprises to bypass the recruitment phase, avoid technical debt, and achieve a much faster speed-to-market.