In the realm of enterprise Customer Experience (CX), the era of frustrating, rule-based “decision tree” chatbots is officially over. Today’s consumers expect instant, human-like, and contextually aware interactions. Generative AI and Large Language Models (LLMs) have made this level of conversational AI possible.
However, deploying an LLM directly into a customer-facing environment introduces the single greatest risk in modern software engineering: The AI Hallucination.
A hallucination occurs when an AI confidently presents false information as absolute truth. In a B2B or enterprise context, this is not just an embarrassment; it is a legal liability. If your airline’s chatbot invents a fake refund policy, or your healthcare bot provides incorrect triage advice, your company is legally bound to the AI’s promises and liable for its mistakes.
To successfully automate customer support, engineering teams must fundamentally rethink the generative ai software development lifecycle . You cannot rely on basic prompt engineering. You must build deterministic guardrails around probabilistic models.
In this deep-dive engineering guide, we will explore exactly how to architect conversational AI agents that are mathematically constrained to tell the truth. For organizations that cannot afford a single hallucination, MindRind specializes in secure generative ai application development , building custom chatbots guaranteed to protect your brand reputation.
Chapter 1: The Anatomy of an AI Hallucination
To cure the disease, you must first understand the pathogen. Why do state-of-the-art models like GPT-4o or Claude 3.5 hallucinate in the first place?
CTOs often mistake LLMs for search engines or databases. They are neither. An LLM is a probabilistic “next-token prediction” engine. When a customer asks a question, the LLM does not “look up” the answer in a database; it calculates the statistical probability of which word should logically follow the previous word, based on billions of parameters trained on the public internet.
If the LLM lacks the specific context of your company’s internal return policy, it will simply predict the most mathematically common return policy found on the internet and present it to your customer as a fact.
It is critical to understand: Hallucination is not a “bug” in the software; it is the core feature of generative creativity. To stop it, backend developers must strip the AI of its creative freedom when answering factual customer queries.
Chapter 2: The Antidote: Strict RAG Architectures
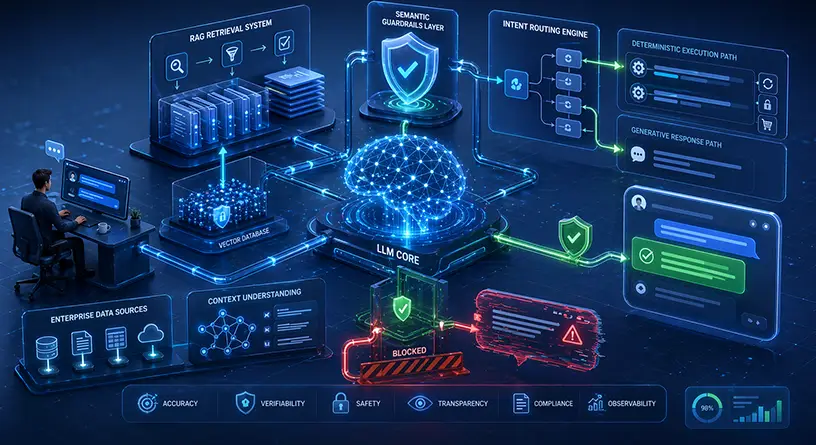
The foundational architecture for a hallucination-free chatbot is Retrieval-Augmented Generation (RAG). RAG acts as the bridge between the LLM’s conversational abilities and your company’s actual, factual knowledge base.
Grounding the AI in Reality
Instead of allowing the AI to answer from its pre-trained memory, a RAG pipeline intercepts the customer’s message.
- Vector Search: The backend converts the customer’s question into a mathematical embedding and searches your secure Enterprise Vector Database (which contains your FAQs, product manuals, and company policies).
- Context Injection: The system retrieves the exact, factual paragraph related to the user’s question.
- Strict Prompting: The prompt sent to the LLM is structured aggressively: “You are a customer support agent. Answer the user’s question using ONLY the provided context below. If the answer is not contained in the context, you must reply: ‘I do not have that information, let me connect you to a human.’ Do not invent information.”
By using RAG to stop hallucinations , you effectively turn the LLM from a creative writer into a strict reading comprehension engine. The model is mathematically constrained by the retrieved text, driving the hallucination rate down to near absolute zero.
Chapter 3: Designing Semantic Output Guardrails
While RAG solves 95% of hallucination issues, enterprise-grade systems require a “belt and suspenders” approach. What happens if the vector search retrieves the wrong document, or a clever user uses a “Jailbreak” prompt to trick the AI into ignoring the RAG instructions?
To ensure 100% compliance, engineering teams must implement Semantic Guardrails (such as Nvidia’s NeMo Guardrails or Meta’s LlamaGuard).
Dual-Model Verification (The Watchdog)
A hallucination-free architecture does not rely on a single LLM. It uses a dual-model verification system.
- The Generator Model: This is the primary LLM (e.g., GPT-4) that formulates the conversational response based on the RAG context.
- The Evaluator Model (The Guardrail): Before the text is sent back via the chat interface to the customer, the response is intercepted by a smaller, incredibly fast secondary model (e.g., a localized Llama 3 8B).
- The Logic Check: The Evaluator model’s only job is to compare the Generator’s response against the original retrieved documents. If the Evaluator detects any claim, statistic, or policy in the response that is not explicitly written in the source documents, it flags it as a hallucination, blocks the message, and triggers a fallback response.
Executing this dual-model check requires a highly optimized, low-latency backend. If you do not build a scalable LLM architecture , this verification loop will cause the chatbot to take 10+ seconds to reply, ruining the customer experience.
Chapter 4: Intent Recognition and Hybrid Routing
A purely generative AI chatbot is great for answering questions, but enterprise customer support is not just about answering questions; it is about taking action. If a user says, “Cancel my subscription,” you do not want the AI to generate a paragraph explaining how to cancel it; you want the backend to actually execute the API call to Stripe and cancel it.
To achieve this safely without the AI hallucinating API payloads, elite development teams use a Hybrid Routing approach.
Combining Deterministic Logic with Probabilistic AI
Before a user’s message hits the LLM, it is routed through an Intent Recognition Engine (such as Google Dialogflow CX or Rasa).
- Actionable Intents: If the engine detects a high-confidence actionable intent (e.g., “Reset Password,” “Check Order Status,” or “Transfer Funds”), it bypasses the generative LLM entirely. The chatbot executes a strict, deterministic script and triggers the backend API directly.
- Conversational Intents: If the user asks a complex, open-ended question (e.g., “What is the difference between your Premium and Enterprise tiers?”), the routing engine forwards the query to the generative RAG pipeline we discussed in Chapter 2.
This hybrid approach ensures that highly sensitive actions (especially in banking or health) are handled with 100% deterministic safety. To understand how critical this hybrid routing is for compliance, review the architectures used in top-tier finance bots and healthcare solutions .
Chapter 5: Managing Conversational State and Memory
A hallucination-free chatbot must also be contextually aware. If a user asks, “How much is the Enterprise plan?” and then follows up with, “Does it include 24/7 support?”, the AI must remember that “it” refers to the Enterprise plan.
Because LLMs are stateless (they forget everything after the API call ends), backend engineers must build a memory management system.
The Danger of the “Infinite Context Window”
The amateur approach to memory is passing the entire chat history back to the LLM with every new message. This is an architectural disaster. As the conversation grows longer, the prompt becomes massive.
- Hallucination Risk: Large prompts cause the LLM to suffer from the “Lost in the Middle” phenomenon, increasing the likelihood of hallucinations as it forgets instructions.
- Financial Ruin: You are billed per token. Sending thousands of tokens of chat history for every single user reply will destroy your SaaS margins.
Memory Compression Techniques
Instead of sending raw chat history, your backend must asynchronously use a smaller, cheaper LLM to summarize previous turns into a compressed “State Object.” This keeps your prompt payloads small and mathematically dense, which directly lowers the overall cost of custom chatbot dev while improving accuracy and latency.
Build a Hallucination-Free Enterprise Bot with MindRind
Automating customer support with generative AI can save an enterprise millions of dollars in call-center overhead, but only if the chatbot is built on a zero-trust, mathematically grounded architecture. You cannot risk your brand’s reputation on a bot that guesses the answers.
At MindRind, our machine learning engineers specialize in generative ai development solutions that prioritize absolute factual accuracy. We do not just connect APIs; we build custom RAG pipelines, deploy dual-model semantic guardrails, and integrate intent-routing engines that safely execute backend tasks.
Ensure your customer support AI is 100% accurate, 100% of the time. Contact MindRind today to architect a hallucination-free enterprise chatbot.
Frequently Asked Questions
Hallucinations occur because Large Language Models (LLMs) are probabilistic text generators, not databases. They predict the next logical word based on training data. If they lack specific factual context about your company, they will mathematically guess the most plausible-sounding answer, presenting fake information as truth.
Retrieval-Augmented Generation (RAG) connects the LLM to a secure Vector Database containing your company’s actual documents. When a user asks a question, the backend retrieves the exact factual document and forces the LLM to answer using only that document, effectively removing its ability to invent facts.
Semantic guardrails are secondary, highly focused AI models (like LlamaGuard or NeMo) that act as a security checkpoint. Before an AI’s response is shown to a customer, the guardrail model evaluates the text to ensure it does not contain hallucinations, toxic language, or unauthorized promises.
Yes, but it requires a “Hybrid Routing” architecture. Instead of letting the generative AI guess how to trigger an API, the system uses an Intent Recognition engine (like Dialogflow). When the user asks for a refund, the system triggers a strict, hard-coded backend script to execute the API call safely.
Sending massive chat histories with every API request (known as stuffing the context window) drastically increases your token costs. Furthermore, it degrades the LLM’s accuracy, causing it to lose focus on the strict system prompts and increasing the likelihood of a hallucination.
Yes. In 2026, the best enterprise chatbots are hybrid. They use deterministic, rule-based logic to handle sensitive actions (like resetting passwords or processing payments) and use generative AI (RAG) to handle complex, open-ended conversational FAQs.
For factual accuracy, both can be safe if restricted by a proper RAG pipeline. However, for maximum data privacy especially in healthcare or banking hosting a fine-tuned open-source model (like Llama 3) on your own Virtual Private Cloud (VPC) ensures customer conversations never leave your servers.
A basic AI wrapper can cost $25,000, but it will hallucinate. Building an enterprise-grade, hallucination-free chatbot requires complex data engineering (ETL pipelines, Vector Databases, Semantic Guardrails). The Total Cost of Ownership (TCO) for this level of custom development typically ranges from $75,000 to $150,000+.