For Chief Technology Officers (CTOs) and Enterprise IT buyers, moving from a generative AI prototype to a production-ready application often brings severe “sticker shock.”
Unlike traditional SaaS development, where costs are highly predictable and center around software engineering hours and standard AWS database hosting, generative AI introduces entirely new economic variables. You are no longer just paying for code; you are paying for mathematical compute, vector storage, and massive GPU cluster rentals.
Underestimating these costs can destroy your software profit margins within weeks of deployment. To successfully secure a budget from your board of directors, you must accurately calculate the Total Cost of Ownership (TCO), dividing your budget into Capital Expenditure (CapEx) for the initial build, and Operational Expenditure (OpEx) for ongoing inference and maintenance.
In this comprehensive financial breakdown, we will dissect the exact costs of building an enterprise AI ecosystem in 2026. Before finalizing your budget, we highly recommend reading our complete generative ai software development guide to understand the technical lifecycle you are funding.
If your organization wants a precise, mathematically driven estimate for your unique roadmap, partnering with a premium custom generative ai development services provider like MindRind ensures you build an architecture that is both powerful and financially viable.
Chapter 1: The Three Tiers of Enterprise AI Pricing
There is no “one size fits all” price tag for generative AI. The cost is entirely dependent on the architecture your engineering team chooses. In 2026, enterprise AI development falls into three distinct pricing tiers:
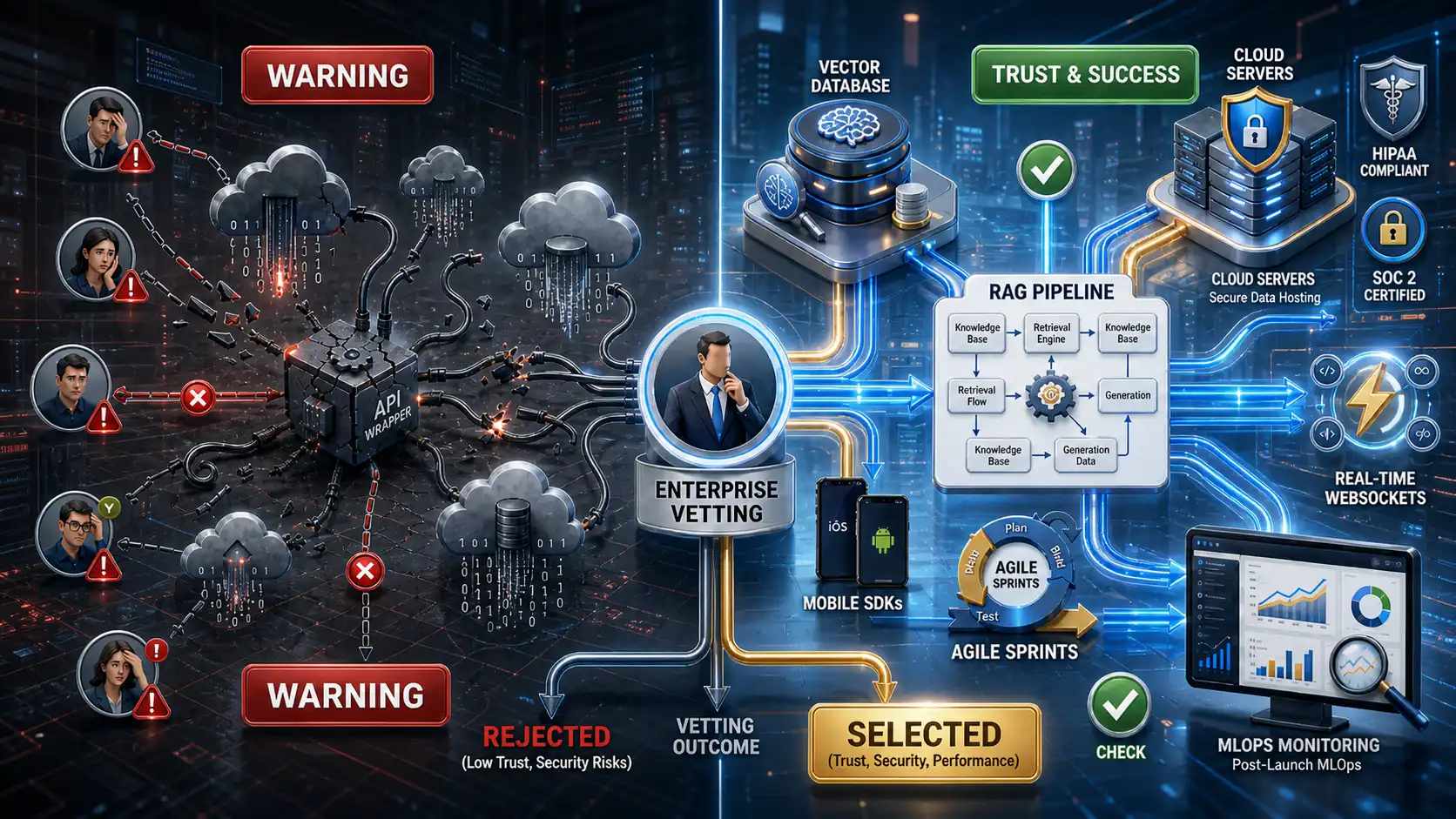
Tier 1: API Wrappers and Workflow Automations ($25,000 – $50,000)
This is the entry-level tier for B2B enterprises. It involves building a custom user interface and backend logic that connects directly to proprietary foundation models (like OpenAI’s GPT-4o or Anthropic’s Claude 3.5).
- What you get: Automated email drafting, CRM data summarization, and basic internal chatbots.
- Why it costs this much: The development is straightforward. The budget goes toward backend integration, building API Gateways, setting up rate limits, and designing basic LangChain orchestrations.
Tier 2: RAG Systems & Custom Knowledge Bases ($75,000 – $150,000+)
If you want the AI to answer questions based strictly on your company’s private data (HR policies, financial documents, proprietary code), you must build a Retrieval-Augmented Generation (RAG) architecture.
- What you get: A hallucination-free AI assistant that acts as a secure, hyper-intelligent search engine for your enterprise.
- Why it costs this much: Building the LLM connection is the easy part. The high cost of RAG pipelines comes from the intense Data Engineering required. Your team must build ETL (Extract, Transform, Load) pipelines to clean your unstructured data, convert it into mathematical embeddings, and store it in enterprise-grade Vector Databases.
Tier 3: Fine-Tuned Open-Source & Sovereign AI ($200,000 – $500,000+)
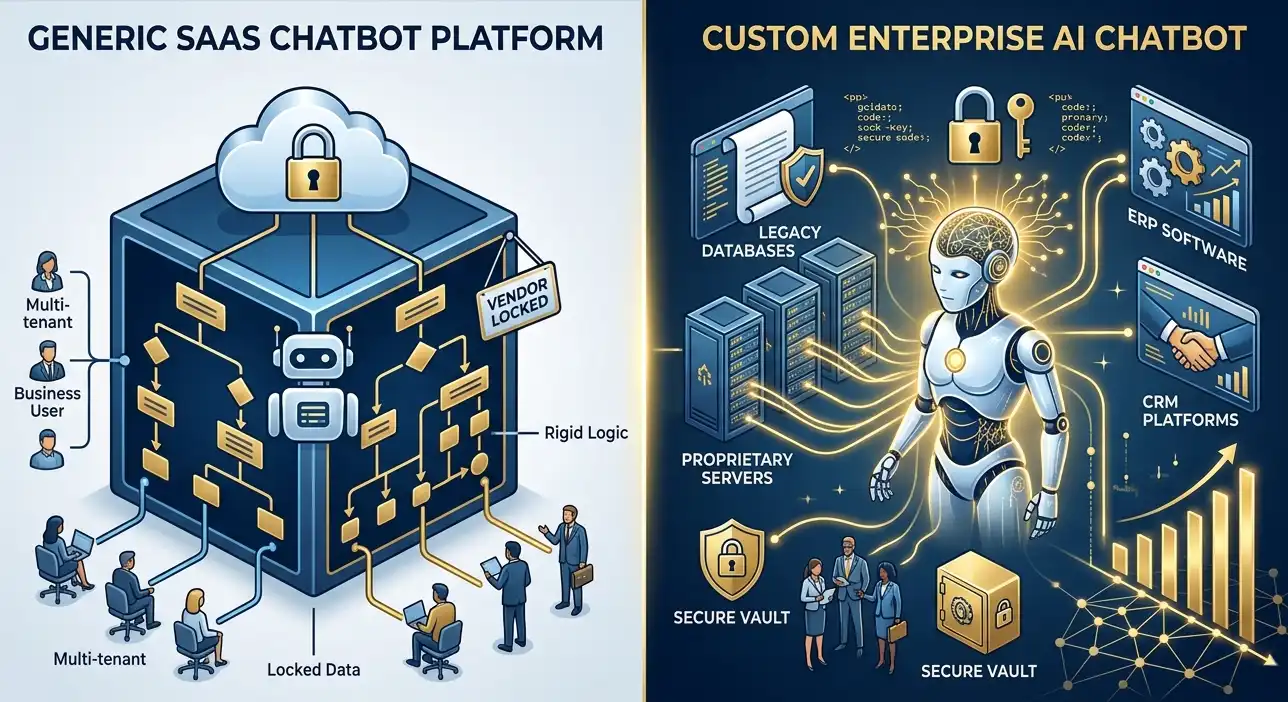
This is the ultimate tier, used by defense contractors, high-compliance healthcare providers, and massive tech enterprises. It involves taking an open-source model (like Meta Llama 3 70B), fine-tuning it on your proprietary data, and hosting it on your own air-gapped Virtual Private Cloud (VPC).
- What you get: Total data sovereignty, zero vendor lock-in, and highly specialized AI behavior.
- Why it costs this much: The upfront CapEx is massive. You must pay elite Machine Learning Engineers, curate massive datasets, and rent high-performance NVIDIA GPU clusters for the training phase. If you are debating whether this tier is right for you, you must deeply analyze the cost of open-source vs proprietary models .
Chapter 2: CapEx vs. OpEx in Generative AI
To avoid bankrupting your IT department, you must understand how generative AI shifts traditional software economics.
CapEx (Capital Expenditure) – The Upfront Build
This is the money you spend before the application ever reaches an end-user.
- Data Curators and MLOps Engineers: AI talent is scarce and expensive.
- Model Training/Fine-Tuning: Renting a cluster of NVIDIA H100s to train a model can cost $10,000 to $40,000+ depending on the parameter size and dataset.
- Security Architecture: Building the dynamic data masking, VPC routing, and Role-Based Access Control (RBAC) required for enterprise compliance.
OpEx (Operational Expenditure) – Ongoing Inference
This is the hidden killer of SaaS profit margins. OpEx is the recurring cost to keep the AI “thinking” (Inference) and maintaining the infrastructure.
- Tokenization: Paying per word generated.
- Vector Database Hosting: Paying Pinecone or Milvus to keep your company’s data indexed in RAM for sub-second retrieval.
- Continuous Evaluation (Drift Monitoring): AI models degrade over time. You must pay for MLOps pipelines to continuously monitor the AI’s output for hallucinations or toxicity.
Chapter 3: Decoding Tokenization and API Costs
If you choose Tier 1 or Tier 2 (using third-party APIs), your primary OpEx constraint will be “Tokens.”
A token is roughly 3/4ths of an English word. Providers charge you two different rates: one rate for the Input Tokens (the prompt you send to the AI) and a higher rate for the Output Tokens (the answer the AI generates).
The “Hidden Context” Cost multiplier
Many CTOs calculate costs based on the user’s prompt. “A user asks a 20-word question, so I only pay for 20 tokens.” This is mathematically incorrect.
In a RAG system, when a user asks a 20-word question, your backend retrieves 5 pages of relevant company documents (approx. 3,000 words) and invisibly injects them into the prompt to give the AI context. Furthermore, to maintain a conversation, you must send the entire chat history back to the AI with every single request.
Suddenly, that “20-word question” requires sending 5,000 tokens to the API. If you have 1,000 employees asking 10 questions a day, you are sending 50 Million tokens daily. At enterprise scale, this can result in API bills exceeding $30,000 a month if you do not engineer semantic caching and prompt-compression techniques into your gateway.
Chapter 4: GPU Cloud Compute Costs (The Infrastructure Bill)
If your enterprise chooses the ultimate security route—hosting an open-source model like Llama 3 or Mistral within your own Virtual Private Cloud (VPC)—you eliminate API token costs completely. However, you trade API bills for Cloud Compute bills.
Foundation models require massive amounts of VRAM (Video RAM) to run. Traditional server CPUs cannot handle the parallel processing required by neural networks. You must rent specialized cloud instances powered by GPUs (like the NVIDIA A100 or the flagship NVIDIA H100) from providers like AWS (EC2 P5 instances), Microsoft Azure, or Google Cloud.
The True Cost of GPU Hosting
- Idle Costs: Unlike Serverless functions that scale to zero when not in use, an LLM must be loaded into the GPU’s memory and kept “warm.” Renting an 8x H100 GPU cluster on AWS can cost upwards of $20 to $30 per hour. If you keep this server running 24/7/365, your baseline infrastructure cost can easily exceed $15,000 to $20,000 per month, just to keep the AI online.
- Scaling Spikes: If your SaaS platform experiences a sudden surge in traffic, a single GPU cluster will bottleneck. You must provision auto-scaling GPU groups, which multiplies your infrastructure OpEx during peak hours.
To reduce these costs, elite AI engineering teams use techniques like Quantization (compressing a massive 16-bit model into a smaller 4-bit model so it fits on cheaper GPUs) and optimized inference engines like vLLM.
Chapter 5: The Cost of Talent (In-House vs. Outsourcing)
The most expensive variable in generative AI software development is not the silicon; it is the human capital.
Building a production-ready AI ecosystem requires a specialized team. A standard web development squad cannot build an LLM architecture. You need:
- AI/ML Architects: To design the vector flow and prompt pipelines.
- Data Engineers: To build the ETL pipelines that clean your unstructured data.
- MLOps Engineers: To deploy the models to AWS, manage Kubernetes clusters, and monitor for model drift.
In 2026, the average salary for a Senior Machine Learning Engineer in the US exceeds $200,000 per year, excluding equity and benefits. Building a complete internal AI division will easily cost an enterprise over $1 Million annually in payroll alone.
Because of this severe talent shortage and high CapEx, the majority of B2B enterprises find it vastly more economical to partner with a specialized agency. To see the exact financial and strategic breakdown of this decision, read our comprehensive guide on hiring a generative AI development company versus building an in-house division.
Chapter 6: Calculating Enterprise ROI (The Financial Justification)
When a CTO presents a $250,000 CapEx budget for a custom AI build, the CFO’s immediate question is: “What is the ROI?”
Generative AI is not an IT expense; it is an operational multiplier. The high initial costs are offset by extreme reductions in human labor and massive gains in software scalability.
- Customer Support Deflection: If an AI chatbot successfully resolves 60% of Tier 1 support tickets, an enterprise can save hundreds of thousands of dollars in call-center staffing.
- Developer Productivity: Integrating AI coding agents into your CI/CD pipeline can accelerate software delivery by 30-40%, drastically reducing the time-to-market for your core products.
- Automated Compliance: In highly regulated industries, AI can automate the auditing of thousands of documents in seconds, a task that would take human lawyers weeks. For real-world financial metrics, explore the extreme ROI of generative AI solutions for healthcare and finance .
Budget Your AI Build with MindRind
Building custom generative AI without a strict financial and architectural roadmap is a recipe for runaway cloud bills and failed deployments. You need a partner who understands both the deep vector mathematics and the strict unit economics of SaaS infrastructure.
At MindRind, we are the premier generative ai development services in usa (<- Focus Keyword). We provide our enterprise clients with exact, mathematically driven TCO (Total Cost of Ownership) calculations before we write a single line of code. From cost-efficient API gateway routing to fully air-gapped VPC deployments, we build architectures that are both incredibly powerful and financially viable.
Stop guessing your AI costs. Contact MindRind today for a detailed architectural audit and a precise project estimate.
Frequently Asked Questions
A basic internal chatbot using proprietary APIs (like OpenAI) can cost between $25,000 and $50,000 to develop. However, an enterprise-grade, hallucination-free chatbot utilizing a secure RAG (Retrieval-Augmented Generation) pipeline and vector databases typically costs between $75,000 and $150,000.
For low-traffic applications and prototypes, the OpenAI API is significantly cheaper because you only pay for the tokens you use. However, for high-traffic enterprise applications (millions of queries per month), the cost of API tokens will surpass the fixed monthly cost of renting cloud GPUs, making hosting an open-source model the cheaper long-term option.
When using proprietary APIs, you are billed by “Tokens” (which roughly equal 3/4ths of a word). You pay one rate for the prompt you send (Input Tokens) and a slightly higher rate for the response the AI generates (Output Tokens). Large prompts containing heavy document context can cause token costs to skyrocket.
Vector databases (like Pinecone or Weaviate) are required for RAG architectures to give the AI memory. Because vector search requires complex mathematical calculations (cosine similarity), the data must be kept in high-speed RAM (Memory) rather than cheap hard drives. Enterprise-grade RAM hosting is expensive.
Renting top-tier enterprise GPUs (like the NVIDIA H100 or A100) on AWS, Azure, or GCP is expensive. A cluster large enough to run a 70-Billion parameter open-source model can cost anywhere from $10,000 to $30,000 per month, depending on your auto-scaling configuration and sustained usage.
MLOps (Machine Learning Operations) is the practice of maintaining AI in production. Unlike traditional software, AI models suffer from “Drift” and data degradation over time. You must pay ongoing salaries or agency retainers to monitor the AI’s accuracy, update vector databases, and patch security vulnerabilities.
Yes. While the upfront CapEx is high, generative AI yields massive ROI by reducing Operational Expenditures. It drastically reduces the need for large customer support teams, accelerates software development timelines, and automates hundreds of hours of manual data entry and document analysis.
No, building an in-house team is usually much more expensive. The average salary for a single Senior ML Engineer exceeds $200,000. Building a full team (Data Engineers, MLOps, Architects) costs over $1M annually. Partnering with a specialized AI agency converts these massive payroll costs into a fixed, predictable project fee.