For Chief Technology Officers (CTOs) and VPs of Engineering, building an enterprise-grade Artificial Intelligence system is no longer just a research experiment; it is a core business requirement. However, when transitioning from a basic prototype to a production-ready application, technical leaders face a critical architectural crossroad: Should your engineering team use Retrieval-Augmented Generation (RAG) or Fine-Tuning?
Both methodologies aim to solve the exact same problem the biggest limitation of out-of-the-box Large Language Models (LLMs): their complete lack of domain-specific, proprietary knowledge. If you ask a standard model to summarize your company’s latest Q3 financial compliance report, it will either confidently invent a fake answer (hallucination) or state that it does not have access to that information.
Choosing the wrong architectural path to solve this problem can lead to skyrocketing cloud compute costs, severe data privacy risks, and delayed deployment timelines.
In this comprehensive, deep-dive technical breakdown, we will evaluate RAG and Fine-tuning across accuracy, latency, cost, and implementation speed to help you make the right engineering decision for 2026. For a broader, high-level overview of the entire AI deployment lifecycle, you can also explore our ultimate guide to generative ai software development .
Chapter 1: The Enterprise Data Problem
Before we compare the solutions, we must clearly define the problem. Foundation models like GPT-4, Anthropic’s Claude, or Meta’s Llama 3 are trained on vast amounts of public internet data. However, their knowledge is “frozen” at the exact moment their training finished.
For a B2B enterprise, your most valuable data is dynamic and private. It lives in secure CRM systems, AWS S3 buckets, internal Confluence wikis, and proprietary codebases. To build a highly functional AI, you must bridge the gap between the LLM’s public reasoning capabilities and your private data silos.
This bridge is built using either RAG, Fine-Tuning, or in the most advanced enterprise use cases, a hybrid of both. If your enterprise requires a highly secure, custom approach from day one, partnering with an expert generative ai application development team is crucial to avoid costly architectural rewrites.
Chapter 2: Deep Dive into RAG (Retrieval-Augmented Generation)
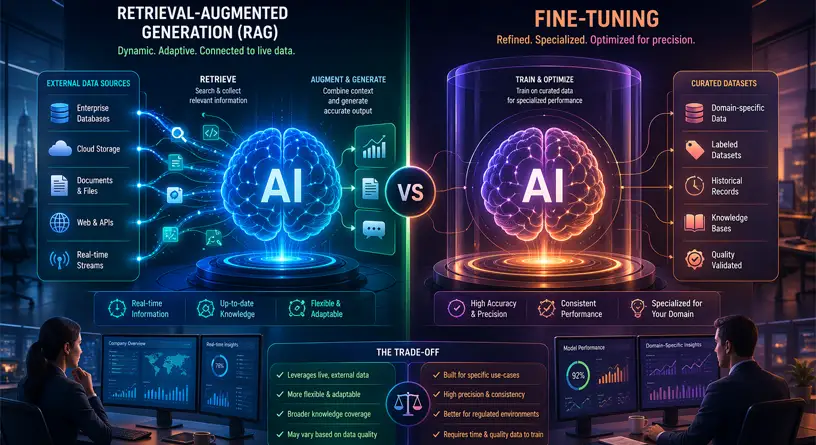
Retrieval-Augmented Generation (RAG) is currently the undisputed industry standard for injecting enterprise data into AI applications.
Rather than changing the internal neural network of the LLM, a RAG architecture intercepts the user’s prompt, searches a localized proprietary database for the exact answer, and feeds that highly relevant context to the LLM to generate a final response.
The Mechanics of a RAG Pipeline
Building a scalable RAG system involves heavy data engineering. The pipeline operates in two distinct phases:
Phase 1: Ingestion and Embedding
- Data Extraction: Your unstructured data (PDFs, Word docs, internal chats) is extracted from your secure servers.
- Semantic Chunking: The data is broken down into smaller, logical paragraphs or “chunks.”
- Vector Embeddings: Using an embedding model, these text chunks are translated into massive arrays of numbers (vectors) that represent the semantic meaning of the text.
- Vector Database Storage: These vectors are stored in highly specialized, high-performance databases like Pinecone, Milvus, or Weaviate.
Phase 2: Retrieval and Generation (Runtime)
- Query Embedding: When an enterprise user asks a question, the query itself is converted into a vector.
- Cosine Similarity Search: The vector database performs advanced mathematical calculations (cosine similarity) to find the data chunks that most closely match the user’s question.
- Prompt Injection: The retrieved data is injected directly into the LLM’s context window alongside the user’s original question.
- Generation: The LLM generates a highly accurate answer based strictly on the provided proprietary context.
The Ultimate Cure for AI Hallucinations
The primary advantage of RAG is factual accuracy. Because the LLM is mathematically constrained to pull answers strictly from the retrieved context, the risk of hallucinations drops to near zero. Furthermore, updating a RAG system is effortless. If your company updates its HR policy, you simply update the vector database. The LLM instantly knows the new policy without needing to be retrained.
The Security Caveat
Passing this proprietary data securely requires a robust infrastructure. If your RAG pipeline is not configured correctly, or if it lacks Role-Based Access Control (RBAC), a junior employee could potentially query the AI and retrieve confidential C-suite documents.
This is why understanding enterprise generative AI security and preventing proprietary data leaks must be your top engineering priority when building a RAG pipeline.
Chapter 3: Deep Dive into LLM Fine-Tuning
Fine-tuning is a fundamentally different approach. Instead of providing the model with a “cheat sheet” at runtime (which is what RAG does), fine-tuning is the process of putting the model back into the classroom.
It involves taking a pre-trained foundation model and continuing its training process on a smaller, highly curated dataset. This physically alters the model weights (the underlying neural network parameters).
How Fine-Tuning Works in 2026
In the past, fine-tuning an entire LLM (Full Parameter Fine-Tuning) required massive clusters of NVIDIA GPUs and cost hundreds of thousands of dollars. Today, engineering teams use Parameter-Efficient Fine-Tuning (PEFT) techniques, specifically LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA).
These techniques freeze the vast majority of the model’s original weights and only train a very small, newly added set of weights. This drastically reduces the compute power needed, making it accessible for B2B tech companies.
When Does Fine-Tuning Actually Make Sense?
Many CTOs mistakenly assume fine-tuning is the best way to teach an AI new facts (like a company wiki). This is a costly mistake. Fine-tuning is terrible for fact retrieval. If you want the AI to memorize that “John Doe is the new VP of Sales,” fine-tuning will likely fail, and updating that fact when John leaves will require retraining the model all over again.
Fine-tuning excels at Task-Specific Behaviors and Formatting.
- Tone of Voice: Teaching the AI to speak exactly like your senior legal counsel.
- Syntax and Coding: Training a model to write code in a highly specific, proprietary programming language used internally by your enterprise.
- JSON/XML Structuring: Forcing the AI to output responses in perfect, unbroken JSON structures for backend API consumption.
Fine-tuning is also the primary strategy when companies choose to bypass public APIs (like OpenAI) entirely. By evaluating open-source vs proprietary models, many enterprises decide to take a smaller open-source model like Llama 3 8B, fine-tune it for a specific internal task, and host it on their own secure hardware.
Chapter 4: Head-to-Head Comparison: RAG vs. Fine-Tuning
To make the right engineering decision, technical leaders must evaluate both methodologies against the specific operational constraints of their enterprise. Here is the definitive technical comparison for 2026:
| Engineering Metric | Retrieval-Augmented Generation (RAG) | LLM Fine-Tuning (LoRA / QLoRA) |
| Primary Use Case | Knowledge retrieval, internal Q&A, searching complex document repositories. | Task automation, enforcing brand tone, structural formatting (e.g., generating JSON/SQL). |
| Data Freshness | Real-time. Instantly updateable. Just add or remove vectors from the database. | Static. Model knowledge is frozen. Requires expensive retraining to update facts. |
| Hallucination Risk | Very Low. The model is mathematically grounded by the retrieved external context. | Medium to High. The model relies on internal weights and can easily invent facts if unsure. |
| Implementation Speed | Fast (Days to Weeks). Relies on data pipelining and prompt engineering. | Slow (Weeks to Months). Requires curating thousands of high-quality training pairs (Datasets). |
| Compute / Hardware | Low. Only requires standard API query costs and Vector DB hosting. | High. Requires specialized GPU clusters (NVIDIA A100s or H100s) for model training. |
Chapter 5: The Economics of Architectural Choice
Your choice between RAG and fine-tuning does not just impact latency and accuracy; it dictates your cloud infrastructure bill for the entire year.
- The Cost of RAG: RAG is heavily dependent on the “Context Window.” Because you are stuffing retrieved documents into the prompt at runtime, your token count per API call increases significantly. Over millions of queries, inference costs can skyrocket. You also must pay for continuous vector database hosting (e.g., Pinecone enterprise tiers).
- The Cost of Fine-Tuning: The upfront cost of fine-tuning is high due to data scientists’ salaries and GPU rental for training. However, the long-term inference cost can be much lower. A fine-tuned open-source 8B parameter model hosted on your own server can process tasks much faster and cheaper per token than sending massive RAG prompts to GPT-4.
This architectural decision will act as the single biggest variable in your overall custom generative ai development cost . If you are budgeting for an enterprise AI rollout, you must calculate both the upfront CapEx (training) and the ongoing OpEx (inference/tokens).
Chapter 6: The 2026 Enterprise Standard: The Hybrid Approach
In 2026, the debate among elite AI engineers is no longer strictly “RAG or Fine-tuning.” The most sophisticated B2B SaaS companies and enterprise leaders are utilizing a Hybrid Architecture.
A hybrid architecture combines the behavioral control of fine-tuning with the factual accuracy of RAG.
- First, the engineering team fine-tunes a highly efficient, open-source model to understand complex industry jargon, mimic the company’s specific tone of voice, and output responses in perfect backend-ready formats.
- Next, a robust RAG pipeline is layered on top of this newly fine-tuned model to feed it real-time, secure, proprietary data from the company’s internal databases.
This delivers the absolute best of both worlds: custom behavior and flawless accuracy. However, orchestrating this requires advanced middleware, load balancers, and vector management. To successfully deploy a hybrid model without crashing your servers, you must design a scalable LLM architecture capable of handling high-throughput enterprise traffic.
Build Your Enterprise AI with MindRind
Navigating vector math, embedding models, LoRA fine-tuning, and MLOps infrastructure requires a specialized team of machine learning engineers. Building this in-house can take months of trial and error.
At MindRind, we don’t just write API wrappers; we are a premium custom generative ai development services provider (<- Focus Keyword used naturally). We architect scalable, secure, and high-ROI generative AI systems from the ground up. Whether you need a massive RAG implementation to search millions of internal legal documents, or a fine-tuned proprietary model hosted on your own secure VPC, we have the technical firepower to deliver.
Ready to build an AI system that actually drives enterprise value? Contact the engineering team at MindRind today to discuss your architecture.
Frequently Asked Questions
Retrieval-Augmented Generation (RAG) connects an LLM to an external database to provide it with real-time, factual context at runtime. Fine-tuning, on the other hand, permanently alters the model’s internal neural weights by training it on a specific dataset to change its behavior, tone, or formatting capabilities.
RAG is significantly better at stopping hallucinations. Because RAG forces the AI to answer questions based only on the provided search results from your proprietary database, it limits the model’s ability to invent fake facts. Fine-tuning does not reliably prevent hallucinations.
While technically possible, it is highly discouraged. Fine-tuning is very inefficient at memorizing dynamic facts. If a fact changes, you must retrain the model. To teach an AI facts that frequently update (like inventory or HR policies), RAG is the industry standard.
Yes. In 2026, the “Hybrid Approach” is the standard for enterprise AI. Engineers fine-tune a model so it understands specific industry jargon and outputs data in the correct format, and then apply a RAG pipeline to that fine-tuned model to feed it real-time, accurate company data.
Upfront, fine-tuning is more expensive because it requires curating a dataset and renting high-powered GPUs (like NVIDIA A100s) for training. RAG is cheaper to build initially. However, at a massive scale, sending huge RAG prompts to paid APIs can become more expensive over time compared to running a small, fine-tuned model internally.
To build a scalable RAG architecture, engineering teams typically use orchestration frameworks like LangChain or LlamaIndex. For storing the mathematical embeddings (data chunks), enterprise-grade Vector Databases such as Pinecone, Milvus, or Weaviate are the industry standard.
If configured correctly, no. In a secure enterprise RAG setup, your data is stored in a private Vector Database. When a prompt is sent to an LLM, only relevant text snippets are shared. To ensure zero data leakage, enterprises can host open-source LLMs within their own Virtual Private Cloud (VPC), ensuring no data is ever sent to third-party API providers like OpenAI.
PEFT (Parameter-Efficient Fine-Tuning) is a modern methodology that allows developers to fine-tune massive models without needing supercomputers. LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) are specific PEFT techniques that freeze the original model weights and only train a very small, new set of weights. This drastically reduces the GPU compute power and cost required for fine-tuning.