When a B2B SaaS company first experiments with Artificial Intelligence, the prototype is usually simple: a basic Python script connecting a frontend interface directly to OpenAI’s API. It works perfectly for a demo with 10 internal users. However, when you attempt to deploy that exact same script to a production environment with 10,000 concurrent enterprise users, the system will catastrophically fail.
You will immediately face severe API rate limits, unpredictable latency spikes, exhausted context windows, and skyrocketing token costs that destroy your software margins.
Transitioning from a basic prototype to enterprise-grade generative ai application development requires a complete architectural paradigm shift. You are no longer just making simple HTTP requests; you are orchestrating a highly complex, probabilistic AI backend that must guarantee high availability, strict multi-tenant data segregation, and sub-second response times.
In this deep-dive engineering guide, we will break down exactly how to architect a fault-tolerant Large Language Model (LLM) backend for modern B2B SaaS platforms. If you are laying the groundwork for an enterprise AI initiative, you should also review our master playbook on building generative ai software to understand the entire AI lifecycle. Furthermore, if your team lacks the internal MLOps expertise to build this infrastructure, MindRind provides elite enterprise generative ai development services to architect and deploy your system from the ground up.
Chapter 1: The Anatomy of a Scalable AI Infrastructure
A traditional B2B SaaS backend relies on deterministic routing. A user requests a specific endpoint, the backend queries a SQL database, and it returns a structured JSON payload in milliseconds.
A generative AI backend is entirely different. It relies on massive neural networks, is computationally heavy, and is highly susceptible to third-party vendor outages (if using public APIs). To build a scalable AI infrastructure, your engineering team must aggressively decouple your core SaaS application logic from the foundation models using robust middleware.
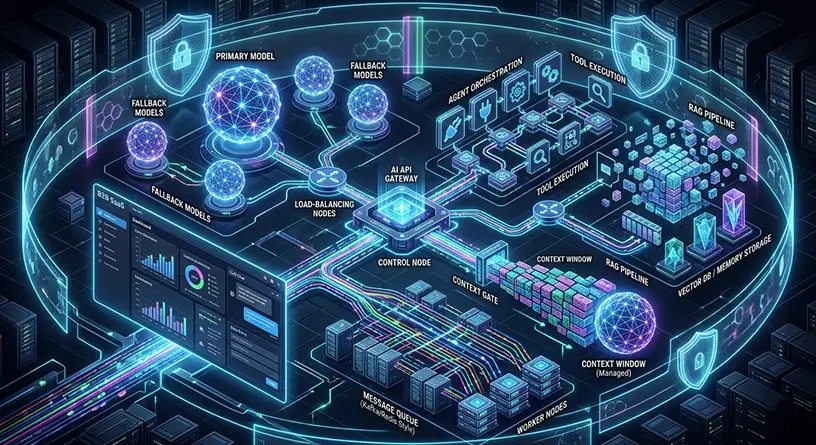
The AI API Gateway (The First Line of Defense)
The golden rule of scalable AI is this: Never allow your SaaS frontend (React, Vue) or standard backend microservices (Node.js, Go) to communicate directly with an LLM.
You must introduce a dedicated AI API Gateway (such as Portkey, Kong AI Gateway, or a custom-configured NGINX reverse proxy tailored for AI traffic). This Gateway serves as your primary traffic controller and handles three critical scalability functions:
- Strict Multi-Tenancy & Authentication: In B2B SaaS, data segregation is paramount. The gateway ensures that User A in Workspace 1 cannot manipulate the prompt history or access the vector data of User B in Workspace 2.
- Rate Limiting & Throttling: If a single SaaS tenant runs a heavy automation script, they could exhaust your global LLM API limits (e.g., Tokens Per Minute constraints from OpenAI or AWS Bedrock), bringing down the system for all other clients. The gateway throttles traffic on a per-tenant basis.
- Semantic Caching: If 50 different users ask your AI, “What is the company holiday policy?”, sending that prompt to the LLM 50 times wastes compute power and money. The gateway uses lightweight embedding models to recognize the semantic similarity of the questions and returns a cached response in milliseconds without ever pinging the LLM.
Intelligent Load Balancing and Fallback Routing
Even the most reliable model providers experience outages and severe latency degradation during peak global hours. If your B2B SaaS relies solely on a single model (e.g., GPT-4o), your application goes offline when their servers go offline.
A scalable LLM architecture requires an intelligent load balancer capable of Fallback Routing.
- How it works: If your primary model times out or throws a 429 Too Many Requests error, your gateway automatically and invisibly reroutes the prompt to a secondary model (e.g., Anthropic’s Claude 3.5 or an open-source model like Mistral).
- This redundancy ensures 99.99% uptime for your end-users, which is a mandatory Service Level Agreement (SLA) requirement for any enterprise-grade SaaS product.
Chapter 2: The Orchestration Layer (LangChain & LlamaIndex)
Once your traffic is securely authenticated and routed through the gateway, it hits the Orchestration Layer. This is where the actual “brain” and business logic of your generative AI application lives.
Managing complex, multi-step AI reasoning requires specialized frameworks. You cannot rely on raw Python scripts to handle state, memory, and tool execution. In 2026, the two dominant frameworks for building LLM backends are LangChain and LlamaIndex.
Designing Chains and Autonomous Agents with LangChain
Simple prompts rarely solve complex B2B problems. You often need the AI to perform a sequence of autonomous actions: fetch unread tickets from a Zendesk API, summarize them, format the output into a specific JSON structure, and then send an alert via Slack.
LangChain allows engineers to build “Chains” and “Autonomous Agents.”
- Instead of writing rigid, step-by-step code, you provide the LLM with a set of tools (e.g., a Web Search Tool, a SQL Query Tool, an internal API caller).
- The Orchestrator dynamically decides which tool to use based on the user’s prompt. It reasons through the problem, executes the tools, and compiles the final answer.
- By maintaining strict modularity in your LangChain setup, you can effortlessly swap out underlying LLMs (e.g., upgrading from Llama 2 to Llama 3) without rewriting your core SaaS application logic.
Data Ingestion and RAG pipelines with LlamaIndex
While LangChain excels at action-routing and agentic workflows, LlamaIndex is the gold standard for connecting LLMs to your private B2B SaaS data pipelines.
Scalable AI requires continuous data synchronization. As users update their profiles, upload PDFs, or change configurations in your SaaS, LlamaIndex ensures these changes are immediately vectorized and made available to the LLM’s memory bank. If you want to understand the exact mechanics of how to feed this data into your models securely, read our deep-dive technical comparison on RAG vs Fine-Tuning architectures .
Chapter 3: Mastering the Context Window
Perhaps the most critical, yet frequently misunderstood, engineering challenge in generative AI application development is managing the Context Window.
The context window is the model’s short-term memory, it is the maximum number of tokens (words, numbers, and code) the LLM can process in a single request. While modern models boast massive context windows (upwards of 128k to 1 million tokens), blindly stuffing the context window is an architectural disaster for two reasons:
- Astronomical Costs: You are billed per token for both input and output. Sending 100,000 tokens of background context for every single user message will bankrupt your SaaS margins within weeks.
- The “Lost in the Middle” Phenomenon: Extensive academic research proves that when LLMs are fed massive amounts of text, their recall accuracy drops significantly. They tend to remember the beginning and the end of the prompt but completely forget or ignore critical information located in the center of the text block.
Dynamic Prompt Engineering and Memory Management
To scale effectively, backend AI engineers must build dynamic context managers.
- Conversation Compression: Instead of passing the entire chat history back and forth with every API call, the system must use a smaller, cheaper model to compress previous turns into concise summaries.
- Vector Retrieval: Prompt Engineering pipelines must be built to inject only the absolute mathematically most relevant data chunks into the prompt right before execution.
- By keeping your context payloads small, dense, and highly relevant, you ensure sub-second response times, slash your token costs, and drastically improve the factual accuracy of the AI.
Chapter 4: Asynchronous Processing and Queue Management
One of the most common mistakes SaaS developers make when transitioning to AI is treating LLM API calls like standard database queries. A standard SQL query takes 50 milliseconds. An LLM generation, especially one utilizing a complex LangChain agent or generating a long report, can take anywhere from 5 to 45 seconds.
If your SaaS backend waits synchronously for the LLM to finish generating, you will tie up your server’s worker threads. If 1,000 users click “Generate Report” simultaneously, your server will exhaust its connection pool, freeze, and crash.
Implementing Message Queues (Redis, Celery, Kafka)
A scalable generative AI architecture must be completely asynchronous.
- When a user submits a prompt, the API Gateway immediately returns a 202 Accepted HTTP status code and a Job ID. The user’s interface shows a loading state (or streams the text).
- Behind the scenes, the prompt is pushed into a high-throughput message broker like Redis, RabbitMQ, or Apache Kafka.
- A fleet of background worker nodes (e.g., Python Celery workers) picks up these jobs from the queue, executes the LangChain orchestration, waits for the LLM response, and then updates the SaaS database or pushes the result to the frontend via WebSockets.
This decoupling ensures that no matter how long the LLM takes to “think,” your core SaaS application remains highly responsive and stable.
Chapter 5: Enterprise Data Security and Multi-Tenant VPCs
In a B2B SaaS environment, you are hosting data for multiple different companies. If the architecture is flawed, an AI agent could accidentally leak Company A’s financial data into Company B’s chat interface. This is a catastrophic failure that will instantly destroy your SaaS business.
Segregating the Vector Database
When building your retrieval architecture, you must implement strict namespace segregation within your vector databases (like Pinecone or Weaviate). Every single vector embedding must be tagged with a tenant_id. Before the LLM is allowed to search the database, the backend must cryptographically verify the user’s tenant_id and restrict the semantic search exclusively to that namespace.
The VPC Requirement
Furthermore, passing sensitive enterprise data to public models (like the consumer version of ChatGPT) violates SOC 2 and GDPR compliances. To scale securely, your SaaS must route traffic through secure enterprise API endpoints (which do not train on user data), or better yet, host open-source models directly within your own Virtual Private Cloud (VPC).
If you are designing the security infrastructure for your SaaS, it is mandatory to review the exact protocols for preventing proprietary data leaks to ensure your architecture is legally and technically compliant.
Chapter 6: Architecting the Conversational Backend
The most common implementation of generative AI in B2B SaaS is the conversational agent or “Copilot.” However, building a scalable copilot is much more complex than just sending text back and forth.
A scalable chatbot backend requires a stateful memory manager. Because the LLM itself is stateless (it forgets everything the moment the API call ends), your backend must store the conversation history in a fast, NoSQL database (like MongoDB or DynamoDB).
When building this conversational interface, your architecture must also include semantic guardrails to prevent the bot from breaking character or giving wrong answers. If your SaaS includes customer-facing AI features, you must learn the exact architectural patterns for building chatbots that don’t hallucinate . This ensures your AI remains factual and mathematically grounded in your SaaS data.
Build Your Scalable AI Backend with MindRind
Transitioning from a traditional SaaS architecture to a probabilistic, asynchronous, and secure LLM backend is a monumental engineering challenge. It requires deep expertise in API gateways, vector mathematics, LangChain orchestration, and cloud MLOps.
You do not have to build this from scratch. At MindRind, our elite machine learning engineers specialize in enterprise generative ai development services (<- Focus Keyword). We architect, deploy, and maintain highly scalable, fault-tolerant AI infrastructures that seamlessly integrate with your existing B2B SaaS platforms.
Stop fighting rate limits and context window errors. Contact MindRind today, and let’s build a scalable AI backend that empowers your enterprise.
Frequently Asked Questions
An LLM architecture is the complete backend infrastructure required to integrate Large Language Models into a software application. It includes API gateways, message queues (like Kafka), orchestration frameworks (like LangChain), vector databases (like Pinecone), and the foundation models themselves.
Connecting a frontend directly to an LLM API is a massive security and scalability risk. It exposes your API keys, makes multi-tenant data segregation impossible, and leaves your software vulnerable to rate limits and denial-of-service attacks. A middleware backend/gateway is mandatory for production.
LangChain is a popular open-source orchestration framework. It allows backend developers to build “Chains” and “Agents” that can link multiple LLM calls together, interact with external APIs, search databases, and manage the complex reasoning required for enterprise AI applications.
To control LLM costs, engineers must implement “Semantic Caching” at the gateway level to reuse answers for similar questions. Additionally, you must dynamically manage the context window by summarizing past conversations, rather than sending the entire chat history with every single API call.
For storing traditional user data, SQL or NoSQL databases are fine. However, to give your LLM “memory” and the ability to search documents, you must use an Enterprise Vector Database, such as Pinecone, Milvus, or Weaviate, which store data as mathematical embeddings.
LLM generation is slow by nature. To keep your application scalable and responsive, your backend must be asynchronous. You should push AI requests into a message broker (like Redis or Celery) for background processing, and stream the generated text back to the user interface using WebSockets or Server-Sent Events (SSE).
You must implement strict namespace segregation in your vector database. Every document embedded into the database must be tagged with a unique tenant_id. Your backend logic must forcefully inject this tenant_id into every semantic search query, ensuring the LLM can only retrieve data belonging to that specific client.
API models (like GPT-4) are easier to implement initially. However, at scale, hosting fine-tuned open-source models (like Llama 3) on your own Virtual Private Cloud (VPC) provides significantly better data security, eliminates third-party rate limits, and drastically lowers your cost-per-token over time.