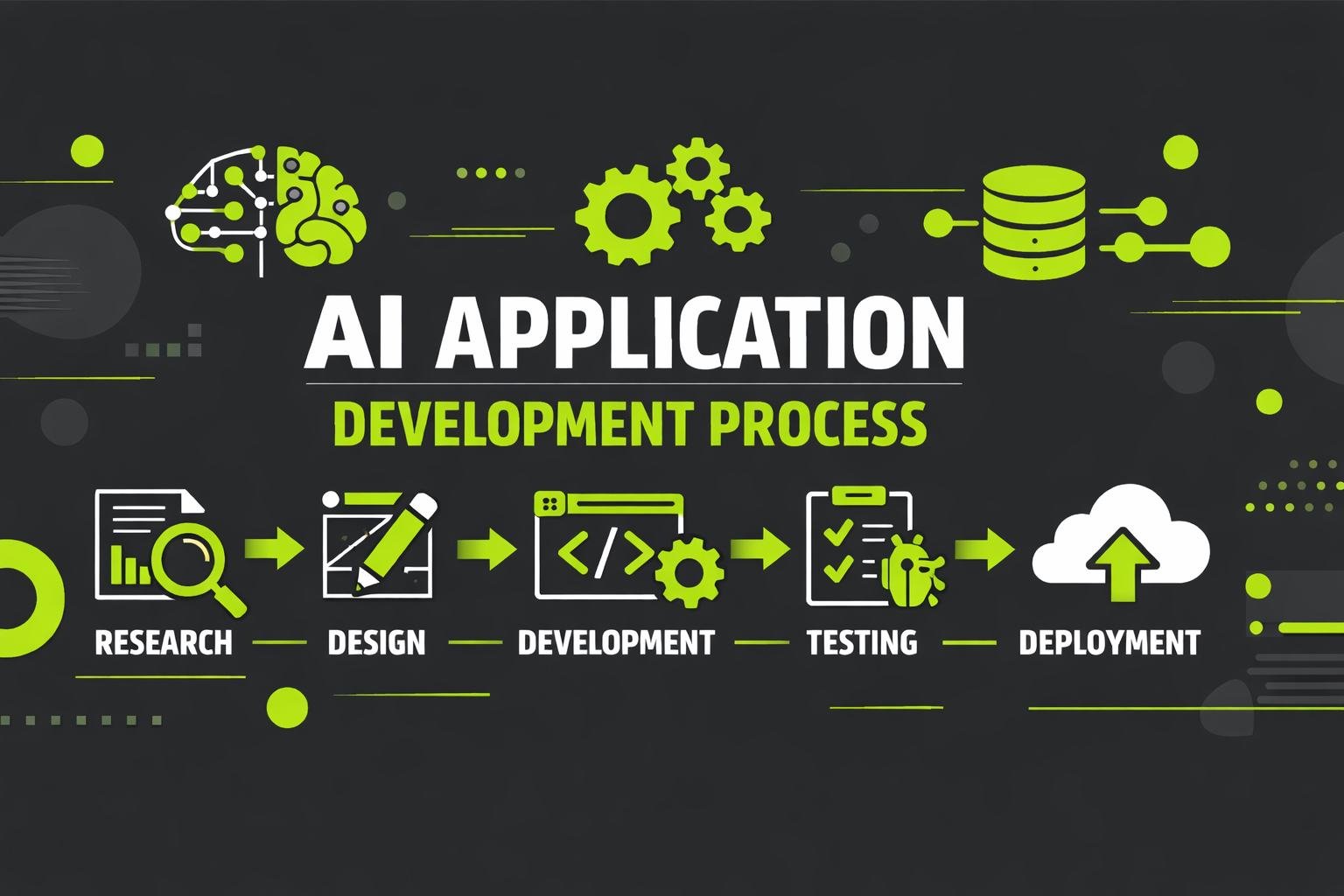
The AI app development process is a structured, iterative lifecycle designed to transform raw data into intelligent, production-ready applications. Unlike traditional software, AI systems do not behave deterministically; their outputs depend on data quality, learning patterns, and continuous optimization. As a result, AI development requires a deeper level of planning, validation, and long-term maintenance.
Organizations that understand the full AI software development lifecycle are better equipped to avoid common pitfalls, control complexity, and deploy AI systems that remain reliable and valuable over time. Below is a detailed, step-by-step breakdown of how AI applications are developed, deployed, and continuously improved in enterprise environments.
Requirement Analysis and Feasibility
Requirement analysis is the foundation of the AI app development process. This stage determines whether AI is the right solution, what problem it should address, and whether the organization is prepared to support it operationally and technically.
Unlike traditional projects, AI initiatives can fail even before development begins if objectives are vague or data realities are ignored. A thorough feasibility phase ensures that AI is applied with purpose rather than experimentation.
Defining Business Objectives and AI Goals
At this stage, organizations translate high-level goals into measurable AI outcomes. Clear alignment between business intent and AI objectives ensures that models are built to deliver real value rather than abstract predictions.
Typical objectives include:
- Improving prediction or classification accuracy
- Automating decision-making at scale
- Reducing manual analysis and response times
- Enhancing system intelligence with data-driven insights
When goals are poorly defined, teams often optimize models without knowing whether the results actually matter to the business.
Identifying the Problem AI Needs to Solve
Not every problem benefits from AI. This step evaluates whether the challenge involves complexity, uncertainty, or scale that rule-based systems cannot handle efficiently.
AI is most appropriate when:
- Outcomes depend on patterns within large datasets
- Rules change frequently or are difficult to codify
- Predictions must adapt as new data arrives
This evaluation prevents unnecessary complexity and ensures AI is used where it adds meaningful advantage.
Assessing Data Availability and Readiness
Data readiness is often the biggest determinant of success. Before development begins, teams assess whether sufficient, relevant data exists and whether it can be accessed reliably and ethically.
This assessment typically includes:
- Identifying data sources and ownership
- Evaluating data consistency and completeness
- Reviewing historical depth and update frequency
Discovering data limitations early avoids costly rework later in the lifecycle.
Technical Constraints and System Dependencies
AI systems must operate within existing environments. During feasibility analysis, teams evaluate application workflows, system dependencies, latency requirements, and operational constraints.
Ignoring these factors can lead to integration issues that surface only after models are built, delaying deployment and increasing risk.
Feasibility Analysis and Risk Identification
This step consolidates technical, data, and operational findings into a clear feasibility decision. Many organizations underestimate early Challenges, particularly those related to data quality, integration complexity, and long-term system maintenance. Identifying risks upfront allows teams to plan realistically and allocate resources appropriately.
Data Collection and Preparation
Data collection and preparation is the most time-intensive stage of the AI app development process and has the greatest impact on model performance. Even highly sophisticated models fail when trained on inconsistent or poorly prepared data.
This phase focuses on transforming raw information into reliable inputs that machine learning models can learn from effectively.
Identifying Data Sources and Data Types
AI systems may rely on a mix of structured, semi-structured, and unstructured data. Understanding the nature of each data type helps teams design appropriate preprocessing strategies and storage mechanisms.
Clear identification of data sources also supports governance, traceability, and long-term maintainability.
Data Collection Strategy and Governance
A structured data collection strategy ensures consistency and accountability. Teams define how data is gathered, refreshed, validated, and secured over time.
Strong governance prevents silent data drift, reduces operational risk, and ensures AI systems remain aligned with real-world conditions rather than outdated assumptions.
Data Engineering and Data Pipeline Design
Data engineering focuses on building automated, repeatable data pipelines that move data from source systems to models efficiently. Well-designed pipelines reduce manual intervention and improve reliability across the lifecycle.
These pipelines typically handle ingestion, transformation, validation, and delivery, ensuring that models receive consistent inputs regardless of scale.
Data Cleaning and Normalization
Raw data often contains noise, missing values, and inconsistencies that distort learning. Cleaning and normalization improve signal quality and reduce bias introduced by irregularities.
This step directly influences model accuracy and stability, making it critical for long-term success.
Feature Engineering for Model Readiness
Feature engineering transforms prepared data into meaningful representations that models can learn from. Effective features capture patterns, relationships, and context that raw data alone cannot express.
Well-designed features often improve performance more than complex model architectures.
Data Validation and Quality Assurance
Before training begins, data validation ensures consistency, correctness, and completeness. Continuous validation protects AI systems from gradual degradation caused by unnoticed data changes.
Model Development and Testing
Model development is where prepared data is transformed into intelligence. This stage requires careful experimentation, evaluation, and refinement to ensure reliable performance under real-world conditions.
Selecting the Right Machine Learning Models
Model selection balances complexity, interpretability, and performance. Choosing overly complex models can increase maintenance costs without delivering proportional benefits.
The goal is to select models that meet performance requirements while remaining stable and manageable.
Training Models with Prepared Data
Training is an iterative process where models learn from historical data. Multiple training cycles are often required to address data issues, refine features, and improve outcomes.
This iterative approach allows teams to validate assumptions early and adjust strategies before deployment.
Model Evaluation Metrics and Benchmarks
Evaluation metrics must align with business objectives rather than relying solely on generic accuracy scores. Proper benchmarking ensures models perform consistently across different scenarios and data segments.
Testing Model Performance and Stability
Testing validates robustness by exposing models to edge cases, variations, and unexpected inputs. This reduces the risk of failures once models are deployed into production environments.
Model Optimization and Fine-Tuning
Optimization improves efficiency and accuracy through controlled adjustments. Fine-tuning balances predictive performance with resource usage, latency, and scalability requirements.
Deployment and Integration
Deployment transitions models from experimentation to operational systems. This phase ensures that AI capabilities are embedded into applications where they can influence real decisions.
Preparing Models for Production Environments
Production preparation includes packaging, versioning, and performance optimization. This step ensures models behave consistently outside development environments.
ML Model Integration into Application Logic
ML model integration connects predictions to application logic, enabling AI outputs to drive actions rather than remain isolated analytics.
Designing Inference Pipelines
Inference pipelines manage how inputs are processed, predictions generated, and outputs delivered. Efficient pipelines ensure stable performance under varying workloads.
Integrating AI with Application Workflows
Successful AI systems align seamlessly with existing workflows. Integration ensures outputs are timely, actionable, and relevant to users.
Validating AI System Components in Production
Post-deployment validation confirms that AI system components operate as expected in live environments, closing the gap between testing and real-world use.
Monitoring and Performance Management
Once deployed, AI systems require continuous oversight. Monitoring ensures that models remain accurate, reliable, and aligned with evolving data patterns.
Key monitoring activities include:
- Tracking prediction accuracy over time
- Detecting data drift and performance decline
- Monitoring latency and system health
- Logging errors and anomalies
Early detection prevents gradual degradation and protects system integrity.
Maintenance & Continuous Improvement
AI systems are living systems that evolve with data and usage patterns. Maintenance ensures long-term relevance and stability.
Model Lifecycle Management
Lifecycle management defines how models are updated, retired, and governed. Structured processes prevent uncontrolled changes and maintain system reliability.
Retraining and Iterative Optimization
Retraining allows models to adapt to new data and shifting conditions. Iterative optimization delivers incremental improvements that compound over time.
Updating Data Pipelines and Workflows
As data sources change, pipelines and workflows must be updated to maintain alignment between data and models.
Common Challenges in the AI App Development Process
Even well-planned AI initiatives face obstacles.
Common issues include:
- Inconsistent or insufficient data
- Complexity of ML model integration
- Performance issues at scale
- Managing evolving Cost & Timeline expectations
Recognizing these challenges early helps organizations plan realistically and sustain long-term success.
Conclusion
The AI app development process is a continuous lifecycle that blends data, models, and systems into intelligent applications. Organizations that invest in disciplined planning, robust data practices, and ongoing maintenance are better positioned to deploy AI systems that scale and improve over time.
Frequently Asked Questions
The AI app development process is a structured lifecycle that includes requirement analysis, data preparation, model development, deployment, monitoring, and continuous improvement. Unlike traditional software, AI systems require ongoing optimization to remain accurate and reliable as data changes.
Traditional software relies on predefined rules and static logic, while AI systems learn from data. This means AI development requires continuous monitoring, retraining, and validation even after deployment. The lifecycle does not end at launch.
Data preparation ensures that information is accurate, consistent, and usable. Poor-quality data leads directly to unreliable models. Cleaning, validation, and feature engineering often consume the most time but have the greatest impact on performance.
ML model integration embeds trained models into applications so predictions influence real-time decisions. This includes connecting models to application workflows, designing inference pipelines, and ensuring stable performance in production.
Retraining frequency depends on how quickly data patterns change. Models should be retrained whenever performance declines, data distributions shift, or new data becomes available that improves learning.
Common risks include poor data quality, lack of monitoring, integration complexity, unrealistic timelines, and underestimating long-term maintenance needs. Addressing these early improves project success.